ContentGen is an open-source JupyterLab extension that generates programming practice questions inside the instructor's own notebook. This paper is an experience report on prototyping the tool, iteratively improving it through evidence-based prompt engineering, and evaluating the generated content against three pedagogical metrics: Correctness, Contextual Fit, and Coherence.
1. Introduction
Creating and revising practice questions is one of the main ongoing challenges for programming instructors. LLMs are a tempting solution, but their outputs vary in quality — subtle errors, hallucinations, and pedagogically weak phrasing force instructors to verify and fix every generation, often costing more than authoring from scratch. Prompt engineering can help, but it is rarely clear how to systematically tell whether a prompt change has actually improved things, especially in an educational context: what does "better" even mean for a generated practice problem?
We present an experience report on the design, implementation, and iterative improvement of ContentGen, a JupyterLab extension that generates practice problems from existing instructional material. To guide our development, we built a dataset of 91 examples from data science courses we teach and developed three binary metrics tailored to our pedagogical goals: Correctness (is the solution code valid?), Contextual Fit (does the question use the lecture's context?), and Coherence (does the question assess the relevant topic?). Using this framework, we compared three prompting strategies — Baseline, Detailed, and Structured — and found that the Structured prompt substantially improved generated-question quality across all three metrics. A usability study with six data science instructors further suggested that our final prototype was perceived as useful and effective. Our contributions are the tool itself, the open-source dataset and evaluation results, and a case study of evidence-based prompt engineering for an educational tool.
2. Instructional Setting and Design Goals
We primarily teach first- and early second-year data science students at a large, public, PhD-granting university. These students learn Python and pandas to manipulate data tables for exploratory analysis and data cleaning. In our courses, we introduce fundamentals with "finger exercises" — short programming problems presented during lectures and office hours, close variants of material students have already seen, designed to build confidence before harder assignments.
Our early attempts to generate these exercises with off-the-shelf tools like the ChatGPT and Claude web apps surfaced three challenges. First, providing context was cumbersome: our materials live in Jupyter notebooks anchored to one or two datasets, and reusing those datasets matters pedagogically — but every prompt required manually re-describing them. Second, it was hard to persuade the LLM to adhere to course-specific idioms (e.g., teaching df.get('salary') before the more standard df['salary']). Third, we had no systematic way to tell whether prompt changes actually improved quality.
These challenges led to three design goals:
- D1 — In-workflow: embed in the interface instructors already use (JupyterLab), not a separate web app.
- D2 — Automatic Context Discovery: the tool gathers the necessary context from the instructional materials itself, rather than forcing the instructor to assemble it.
- D3 — Effective for Instruction: generated questions should be correct, have contextual fit (reuse the lecture's datasets), and be coherent (assess the relevant topic).
3. System Design
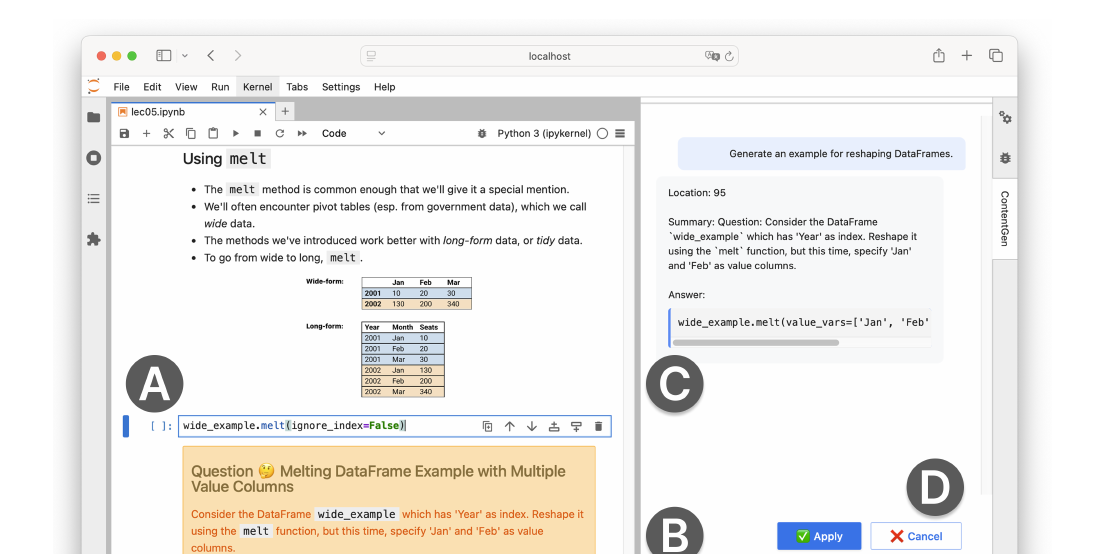
Instructors interact with ContentGen through a sidebar chat inside JupyterLab. They select a notebook cell, optionally type a short prompt, and ContentGen generates a question + answer that appears both in the sidebar and as an inserted cell below the source. From there they can accept, cancel, or follow up. ContentGen is implemented in Python, JavaScript, and the JupyterLab Extension API; all code, prompts, and evaluation data are open-source on GitHub. We exclusively use Gemini 2.0 Flash — more than 95% cheaper per token than flagship models — to see whether a smaller, cheaper model can still produce high-quality content.
Three prompt iterations
We compared three prompting approaches, each adding more structure to the context we sent the LLM:
- Baseline. One paragraph of instructions plus the entire notebook as a JSON string. Mimics copy-pasting a whole lecture into ChatGPT.
- Detailed. Step-by-step instructions that first ask the LLM to generate a code snippet that is a slight variation of the user's selected cell, then generate a question to match it. Also lists the variables currently defined in the notebook.
- Structured. Adds to the Detailed prompt by including an automatically generated summary of the notebook's structure — pedagogical topics, subtopics, functions defined, and datasets used. ContentGen pre-processes the notebook with an LLM call to produce this summary before any user request.
4. Quantitative Evaluation
We purposively selected 91 test cases from the lecture notebooks of two foundational undergraduate data science courses we teach, spanning Python basics, NumPy, pandas, intermediate pandas, data visualization, and scikit-learn. Each test case consists of one notebook cell paired with a brief user prompt designed to guide question generation. For each test case, we ran all three prompt versions of ContentGen — generating an initial 273 question-answer pairs, plus 24 follow-up pairs to simulate instructors iterating on weak outputs, for a total of 297 pairs for evaluation.
Evaluation criteria
We evaluated quality using three binary metrics, developed from pilot studies and our design goals. For data science, a good question must be more than just correct — it has to read clearly and fit the current teaching context.
| Metric | Definition (must satisfy all) |
|---|---|
| Correctness |
The question is logically valid and includes all necessary information to answer it. The solution is accurate with respect to the concepts, and the code is runnable. |
| Contextual Fit |
The question reuses the same dataset or variables for instructional continuity. The question aligns with the topic of the original cell and avoids unfamiliar APIs or concepts not yet introduced. |
| Coherence |
The question is clear and focuses on the most relevant educational topics or concepts. The question is different from the existing notebook cells and worth teaching as an independent example. |
Calibration
Three authors independently rated a randomly sampled subset of 55 question-answer pairs (~18.5% of the total). After independent ratings, the three raters discussed discrepancies and refined shared interpretations. The κ scores indicate substantial agreement for Correctness and Coherence, and almost perfect agreement for Contextual Fit.
| Metric | Agreement Percentage | Fleiss' Kappa κ |
|---|---|---|
| Correctness | 90.9% | 0.772 |
| Contextual Fit | 90.9% | 0.867 |
| Coherence | 87.3% | 0.746 |
In the main round, each rater was assigned a distinct version of ContentGen and independently scored all questions generated by that version on the three binary metrics — 1 if the question met the standard, 0 otherwise. We normalized scores by computing the percentage of questions that received a 1 in each dimension.
Results
The Baseline performed poorly across all metrics, with Contextual Fit scoring only 23%. Failures clustered around questions that invented new datasets, used pandas operations too advanced for the current point in the course, or hallucinated column names. The Detailed prompt drove a dramatic jump in Contextual Fit from 23% to 76%, attributable mainly to explicit instructions on variable reuse and scope alignment. The Structured prompt then achieved the highest scores across the board by giving the LLM a topic-level map of the notebook, not just the raw cells. Coherence improved at every step but remained the lowest of the three metrics — generating pedagogically appropriate questions is harder than getting the code right.
Token usage was dominated by the notebook itself, inserted verbatim into the prompt. Baseline and Detailed used approximately 6,000–9,000 tokens per generation; Structured used about 12,000–16,000 because it involves two LLM calls (one to summarize the notebook, one to generate the question). Despite the increase, we estimate that roughly 700 questions can be generated per U.S. dollar using the Structured version with Gemini 2.0 Flash.
5. Qualitative Evaluation
To externally validate the prototype, we conducted 50-minute, one-on-one, think-aloud usability studies with six participants (P1–P6, three faculty and three teaching assistants) from introductory and intermediate data science courses, all using the Structured prompt. Instructors found ContentGen easy to install and intuitive to use, and reported that the generated questions were generally useful (P1–P6).
When the tool fell short, the failure modes mapped cleanly onto our three quantitative metrics. Instructors almost always ran the generated solution to check for Correctness, noting that errors would "be misleading" for students (P2, P4). Contextual Fit issues arose when a question used a function they didn't "teach . . . until a week later" (P1), disrupting the pedagogical sequence. Coherence problems appeared when a question was "very complicated" (P1) or simply didn't test the intended concept — the goal is to "test the concept, not necessarily the syntax" (P2). Instructors preferred using ContentGen while preparing materials rather than live, citing a lack of trust in the LLM's reliability: "you don't know if it's going to give you a good question" (P1).
6. Discussion
Engineering prompts, context, and metrics
The most surprising part of building ContentGen was that the LLM work — not the JupyterLab integration — was the hard part. And within the LLM work, the genuinely difficult problem was not writing prompts but defining what "better" meant. Correctness, Contextual Fit, and Coherence emerged from our experience as data science instructors, who have different pedagogical needs than instructors of more "traditional" computer science courses. Ensuring a question reused a lecture's dataset (Contextual Fit) was just as important as the question being answerable (Correctness).
Once those metrics were defined, the design space of possible prompts collapsed into something navigable. Crucially, prompt iteration alone plateaued quickly: the jump from Baseline to Detailed was big, but further prompt tweaking did not produce similar gains. Most of our remaining engineering effort went into curating better context — pre-processing the notebook with an LLM call to extract topics, functions, and datasets, then feeding that structured summary to the question-generation call. This aligns with the recent view that context engineering is a more appropriate term than prompt engineering for the work of making LLM-based tools effective.
Using LLMs in practice as educators
Our findings suggest the most effective way to improve LLM-generated content is not intricate prompt design, but careful context curation. Instead of providing an LLM with an entire lecture notebook, instructors may achieve better results by first using an LLM to produce a structured summary of the notebook's topics, functions, and datasets, and then using that summary as the context for a second generation request. More broadly, as LLMs become more capable and cheaper, instructors will spend less time authoring from scratch and more time evaluating and integrating AI-generated content — pointing to a need for tools that help them quickly assess the pedagogical quality of an output and build the necessary trust.
My role
I contributed to system implementation and evaluation as a co-author alongside Jiaen Yu and Ylesia Wu (co-first authors), Ayush Shah, and Sam Lau.
Citation
@inproceedings{yu2026contentgen,
author = {Yu, Jiaen and Wu, Ylesia and Cha, Gabriel and Shah, Ayush and Lau, Sam},
title = {Improving LLM-Generated Educational Content: A Case Study on
Prototyping, Prompt Engineering, and Evaluating a Tool for
Generating Programming Problems for Data Science},
booktitle = {Proceedings of the 57th ACM Technical Symposium on
Computer Science Education V.1 (SIGCSE TS 2026)},
year = {2026},
publisher = {ACM},
address = {New York, NY, USA},
pages = {7},
doi = {10.1145/3770762.3772619}
}DOI 10.1145/3770762.3772619 · Open-source repository. Released under CC BY 4.0.