Classifying human emotions from speech — happiness, sadness, anger, neutrality — using ML over augmented spectrograms. The best model (a CNN) reached 86% accuracy on a 12,000-clip benchmark.
Data
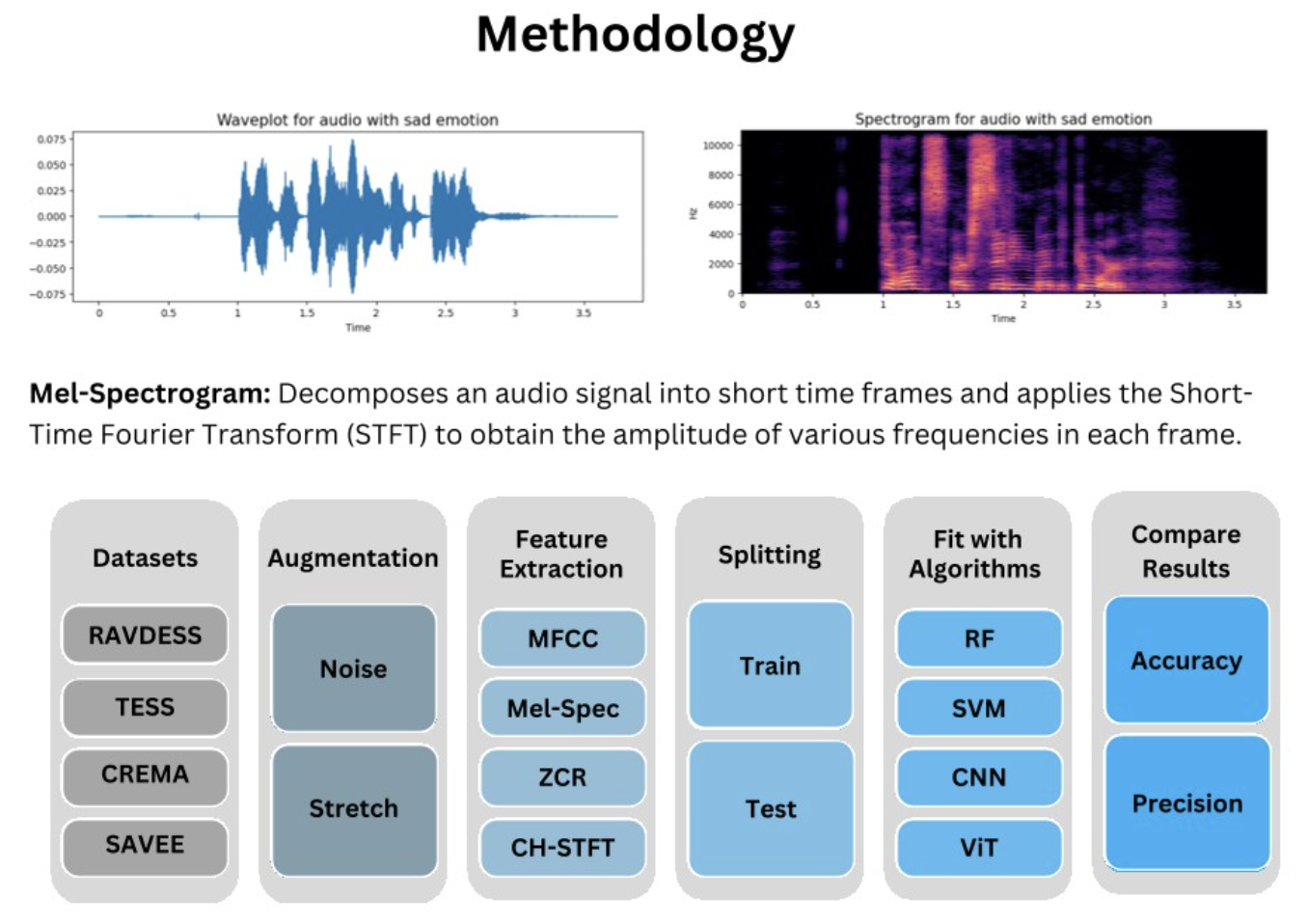
We aggregated and processed 12,000 audio clips drawn from four public emotion-labeled datasets:
- RAVDESS — Ryerson Audio-Visual Database of Emotional Speech and Song
- TESS — Toronto Emotional Speech Set
- CREMA-D — Crowd-Sourced Emotional Multimodal Actors Dataset
- SAVEE — Surrey Audio-Visual Expressed Emotion
Combining datasets meant resolving conflicting label taxonomies, normalizing sample rates, and handling per-corpus speaker bias.
Approach
To simulate real-world acoustic variability, we augmented every clip with noise injection and time-stretching. Each augmented clip was converted into a spectrogram — a visual representation of how its frequency content evolves over time — so we could apply image models alongside audio-specific ones.
We trained and compared four classifiers:
- Convolutional Neural Network (CNN) — best overall,
- Vision Transformer (ViT) — competitive on cleaner subsets,
- Support Vector Machine (SVM) — a strong classical baseline,
- Decision Tree — interpretability check.
Results
- Best model: CNN at 86% test accuracy.
- Failure mode: the CNN was overconfident in some misclassifications — most strikingly, mis-labeling anger as sadness with high probability.
What I took away
The overconfident-misclassification pattern made the interpretability and fairness side of ML feel suddenly very concrete. A model that says it's 95% sure when it's wrong is not a small step away from a model that says it's 95% sure when it's right — those are completely different products in a downstream system. That observation pulled me toward the work on Concept Bottleneck LLMs that I started shortly after.
Built with librosa, scikit-learn, TensorFlow, and a lot of spectrograms. Repo: github.com/gabrielchasukjin/Speech-Emotion-Recognition.